
LSEBMCL: A Latent Space Energy-Based Model for Continual Learning

Continual learning has become essential in many practical applications such as online news summaries and product classification. The primary challenge is known as catastrophic forgetting, a phenomenon where a model inadvertently discards previously learned knowledge when it is trained on new tasks. Existing solutions involve storing exemplars from previous classes, regularizing parameters during the fine-tuning process, or assigning different model parameters to each task. The proposed solution LSEBMCL (Latent Space Energy-Based Model for Continual Learning) in this work is to use energy-based models (EBMs) to prevent catastrophic forgetting by sampling data points from previous tasks when training on new ones. The EBM is a machine learning model that associates an energy value with each input data point. The proposed method uses an EBM layer as an outer-generator in the continual learning framework for NLP tasks. The study demonstrates the efficacy of EBM in NLP tasks, achieving state-of-the-art results in all experiments.
ConfliLPC: Logits and Parameter Calibration for Political Conflict Analysis in Continual Learning

The ConfliLPC framework introduces an innovative integration of Logits and Parameter Calibration (LPC) with the ConfliBERT model, tailored specifically for the nuanced analysis of political conflict and violence. This paper details the development and application of ConfliLPC, highlighting its robust capability to adapt to evolving data landscapes without succumbing to catastrophic forgetting (CF), a common challenge in machine learning models applied to dynamic domains such as political science. ConfliLPC enhances accuracy and adaptability by continually adjusting its parameters to accommodate new information while retaining valuable historical insights. The framework has been rigorously tested across various conflict scenarios, demonstrating superior performance in real-time analysis and predictive tasks. This work serves as a significant contribution to the fields of political science, conflict research, and applied machine learning, providing a powerful tool for analysts and policymakers engaged in the understanding and resolution of political conflict. The experimental results highlight the efficiency of the ConfliLPC method and its capability to minimize CF. Our code is publicly available https://github.com/Xiaodi-Li/ConfliLPC.
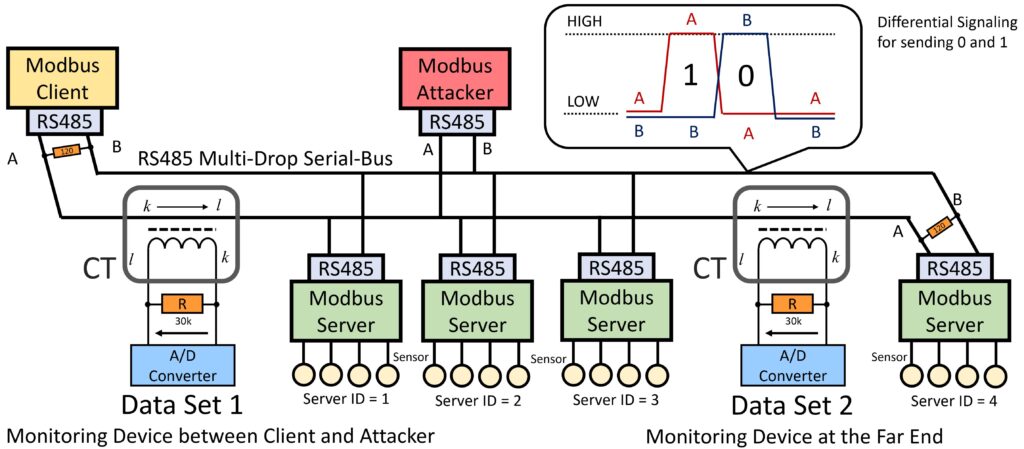
Industrial control systems (ICSs) are getting integrated into cyber-physical systems (CPSs) for a smarter and more energy-efficient society. As they organize the infrastructure of our modern society, cyber-attacks on ICSs may lead to catastrophic disasters if there are no protection, detection, and mitigation schemes. Modbus / RS-485 networks work as the backbone at the edges of ICSs, which security monitoring data on the communication signals comes with tabular forms and only with a few ground truth labels in the practical scenario, which makes the detection of attacks challenging with legacy machine learning. This paper presents a new approach called 2MiCo (Double Mixup and Contrastive) for semi-supervised learning in tabular security data sets. These data sets pose unique challenges for machine learning due to the loss of contextual information and imbalanced data. We address these challenges with a triplet mixup data augmentation approach in the input layer and a common mixup in the hidden layer. Our approach achieves state-of-the-art performance on both binary and multi-class data sets in the Modbus Attack DataSet for AMI (MAMI) compared to other methods. While semi-supervised methods are well-studied in image and language domains, they have been underutilized in security domains, particularly in tabular data sets. 2MiCo demonstrates promise in addressing these challenges and improving the performance of machine learning in security domains.
LPC: A Logits and Parameter Calibration Framework for Continual Learning
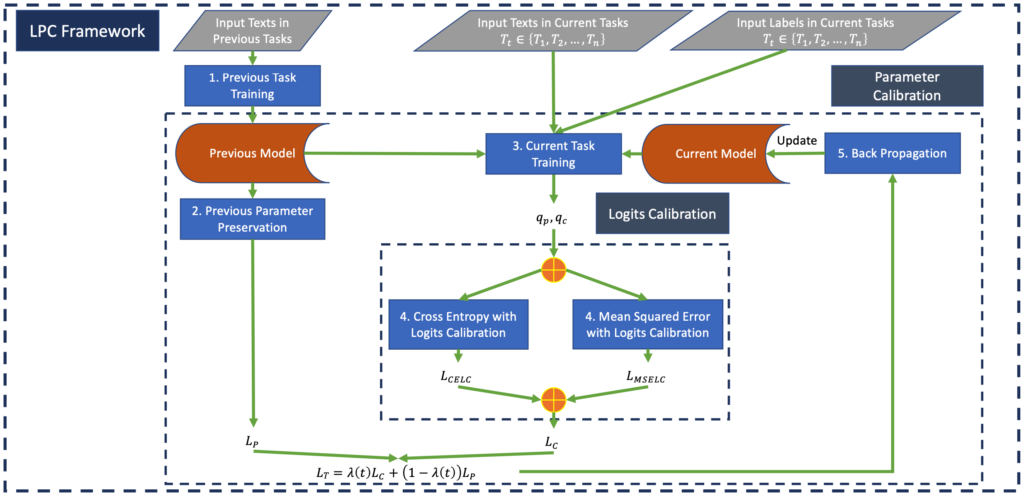
When we execute the typical fine-tuning paradigm on continuously sequential tasks, the model will suffer from the catastrophic forgetting problem (i.e., the model tends to adjust old parameters according to the new knowledge, which leads to the loss of previously acquired concepts). People proposed replay-based methods by accessing old data from extra storage and maintaining the parameters of old concepts, which actually raise the privacy issue and larger memory requirements. In this work, we aim to achieve the sequential/continual learning of knowledge without accessing the old data. The core idea is to calibrate the parameters and logits (output) so that preserving old parameters and generalized learning on new concepts can be solved simultaneously. Our proposed framework includes two major components, Logits Calibration (LC) and Parameter Calibration (PC). The LC focuses on calibrating the learning of novel models with old models, and PC aims to preserve the parameters of old models. These two operations can maintain the old knowledge while learning new tasks without storing previous data. We conduct experiments on various scenarios of the GLUE (the General Language Understanding Evaluation) benchmark. The experimental results show that our model achieves state-of-the-art performance in all scenarios.
MCoM: A Semi-Supervised Method for Imbalanced Tabular Security Data
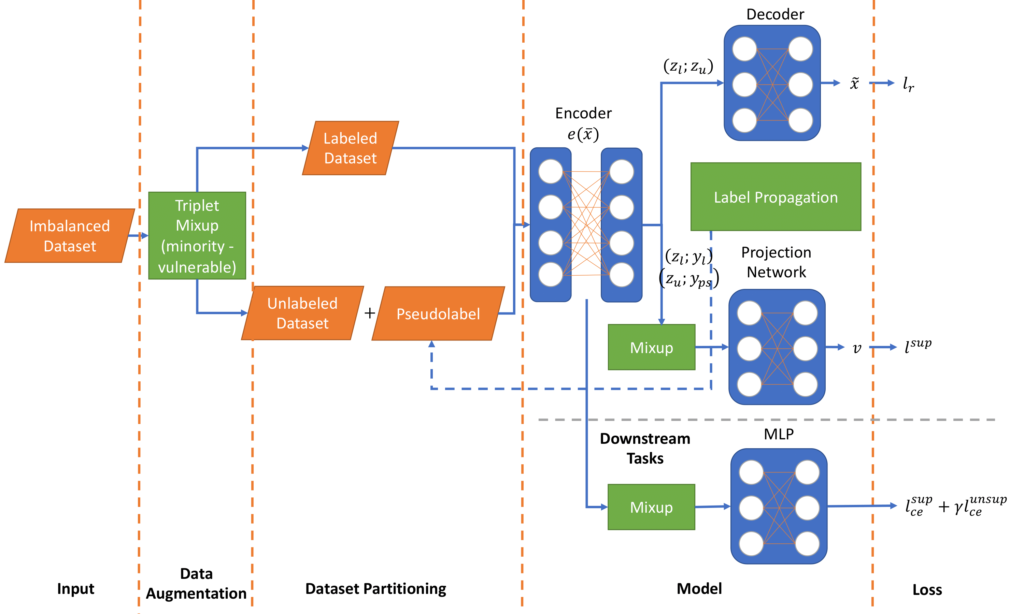
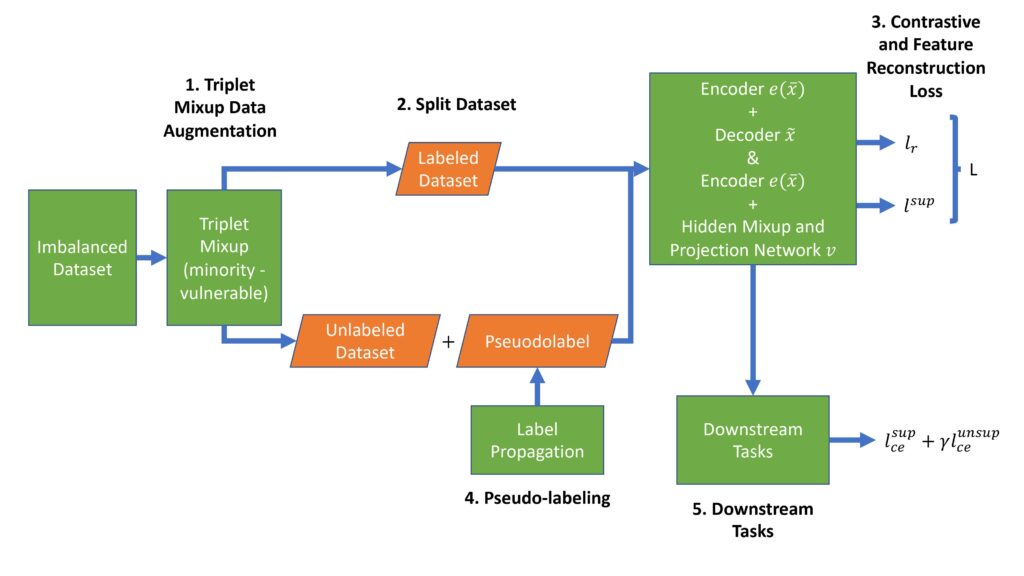
MCoM (Mixup Contrastive Mixup) is a new semi-supervised learning methodology that innovates a triplet mixup data augmentation approach to address the imbalanced data problem in tabular security data sets. Tabular data sets in cybersecurity domains are widely known to pose challenges for machine learning because of their heavily imbalanced data (e.g., a small number of labeled attack samples buried in a sea of mostly benign, unlabeled data). Semi-supervised learning leverages a small subset of labeled data and a large subset of unlabeled data to train a learning model. While semi-supervised methods have been well studied in image and language domains, in security domains they remain underutilized, especially on tabular security data sets which pose especially difficult contextual information loss and balance challenges for machine learning. Experiments applying MCoM to collected security data sets show promise for addressing these challenges, achieving state-of-the-art performance compared with other methods.